
This morning it happened again. Last week I updated my kernel through the yast-updater. And this causes me to recompile my VMWare modules using vmware-config.pl. However: the compilation fails. For info I now run: 2.6.25.20-0.1-default x86_64 (Open Suse).
The compilation failed with the error: '... In function ‘VNetBridgeUp’: /tmp/vmware-config3/vmnet-only/bridge.c:947: error: implicit declaration of function ‘sock_valbool_flag’ ... '.
It took me sometime to get me back to my own earlier post at: http://darwin-it.blogspot.com/2008/11/wireless-network-bridging-with-vmware.html. Here I wrote that I had to add the function in /usr/src/linux/include/net/sock.h.
Open the file in vi (as root).
Search for the line: extern __u32 sysctl_wmem_max;
Right above it copy the following lines:
static inline void sock_valbool_flag(struct sock *sk, int bit, int valbool)
{
if (valbool)
sock_set_flag(sk, bit);
else
sock_reset_flag(sk, bit);
}
Then running vmware-config.pl should succeed.
Good luck. And I hope I remember this the next time I update the kernel.
Monday, 26 January 2009
Wednesday, 21 January 2009
Install Subversion under RedHat Enterprise Linux4
This morning I tried to install Subversion 1.5.1 on Red Hat Enterprise Linux 4. This turned out to be a slightly more complicated than just easy. Because I ran into some dependency issues.
I downloaded Subversion 1.5.1 at: http://summersoft.fay.ar.us/pub/subversion/1.5.1/rhel-4/i386/.
Running rpm gave me the following depencency issues:
rpm -ihv subversion-1.5.1-1.i386.rpm
error: Failed dependencies:
apr >= 0.9.7 is needed by subversion-1.5.1-1.i386
apr-util >= 0.9.7 is needed by subversion-1.5.1-1.i386
libneon.so.27 is needed by subversion-1.5.1-1.i386
neon >= 0.26.1 is needed by subversion-1.5.1-1.i386
To solve this download the following libraries:
Since subversion needed a specific neon-shared-object, I could not do it in one go, because at dependency check the system-object was not there. Therefor I first installed neon and neon-devel:
rpm -ihv neon-0.27.2-1.i386.rpm neon-devel-0.27.2-1.i386.rpm
Preparing... ########################################### [100%]
1:neon-devel ########################################### [ 50%]
2:neon ########################################### [100%]
Then the rest could be installed in one go:
rpm -Uhv subversion-1.5.1-1.i386.rpm apr-0.9.12-2.i386.rpm apr-util-0.9.12-1.i386.rpm
Preparing... ########################################### [100%]
1:apr ########################################### [ 33%]
2:apr-util ########################################### [ 67%]
3:subversion ########################################### [100%]
So I now start off with creating my repository.
I downloaded Subversion 1.5.1 at: http://summersoft.fay.ar.us/pub/subversion/1.5.1/rhel-4/i386/.
Running rpm gave me the following depencency issues:
rpm -ihv subversion-1.5.1-1.i386.rpm
error: Failed dependencies:
apr >= 0.9.7 is needed by subversion-1.5.1-1.i386
apr-util >= 0.9.7 is needed by subversion-1.5.1-1.i386
libneon.so.27 is needed by subversion-1.5.1-1.i386
neon >= 0.26.1 is needed by subversion-1.5.1-1.i386
To solve this download the following libraries:
- The apr and apr-util version 0.9.12 packages at: http://summersoft.fay.ar.us/pub/subversion/1.4.6/rhel-4/i386/
- The neon and neon-devel version 0.27.2-1 packages at http://summersoft.fay.ar.us/pub/subversion/1.5.1/rhel-4/i386/
Since subversion needed a specific neon-shared-object, I could not do it in one go, because at dependency check the system-object was not there. Therefor I first installed neon and neon-devel:
rpm -ihv neon-0.27.2-1.i386.rpm neon-devel-0.27.2-1.i386.rpm
Preparing... ########################################### [100%]
1:neon-devel ########################################### [ 50%]
2:neon ########################################### [100%]
Then the rest could be installed in one go:
rpm -Uhv subversion-1.5.1-1.i386.rpm apr-0.9.12-2.i386.rpm apr-util-0.9.12-1.i386.rpm
Preparing... ########################################### [100%]
1:apr ########################################### [ 33%]
2:apr-util ########################################### [ 67%]
3:subversion ########################################### [100%]
So I now start off with creating my repository.
Friday, 16 January 2009
Change a JHeadstart Workspace for another Jdeveloper Setup on Windows
Aonther problem I ran into in my latest JHeadstart project was that I'm using Linux on my laptop. So all the paths to libraries in my JDeveloper environment are following my setup under Linux. All of my co-workers on the project use Windows. I know, I said it earlier, I'm somewhat stubborn in this.
In the JHeadstart developers guide is stated that in a multi-developer-JHeadstart-project you should ensure that all the developers have the same Developer setup. In my case I turned out to be the only developer on this sub-project. But leaving the project others should be able to go further with it.
So I started my Windows Virtual Machine and took the time to setup a JDeveloper, Tortoise SVN client, download the Working copy of the workspace from SVN. That took me most of the time. Changing the workspace then was done in about a quarter.
JDeveloper Startup Path
JHeadstart and JDeveloper have absolute paths to libraries in the projects. It turns out to be quite handy to have all team members the same path to the libraries (as stated in the JHeartart Developers Guide). To enable that without the need to have each member physically install JDeveloper and the workingcopy of SVN in to the same directory, I crated a batch-file that creates two drives that map to the physical location.
I named the file drives.bat. It sets the s: drive to the folder that contains the trunk folder of your working copy and the w: drive to the home directory of jdeveloper (the root folder that contains the jdeveloper.exe):
subst s: e:\svn
subst w: e:\oracle\product\jdeveloper
Create a shortcut to the jdeveloper.exe on w:\ and start jDeveloper from that shortcut.
Install JHeadstart if not done allready:
In Jdeveloper goto Help=>Check for upates
Click next and choose install from local file.
Choose JHS10.1.3.3.85-INSTALL.ZIP and finisch the wizard.
Edit custom library
I used BPEL libraries because I needed to kickstart a BPEL process from a button in one of the screens. This library turned invalid since it could not find the jar-files following the original paths.
In Model Project properties goto libraries. Edit your custom OraBPEL Library. In my case I added the entries:
Right click on the ViewController project and run Jheadstart Application Generator (JAG). The JAG will change the paths to the JHeadstart libraries according to the startup path of Jdeveloper.
Recompile the Model and the ViewController project.
This ensures you that the changes are applied correctly and the code compiles correctly. Now you can deploy it to your App-server and you should be able to run it using the Embedded OC4J server.
Run the ViewController project
If you add an appropriate ConnectionPool and DataSource in the Embedded OC4J Server (You can do that via Tools => Embedded OC4J Preferences) then you’ll be able to run the SchedulerUI in the Embedded OC4J. If you do so then you're sure the workspace is correct again.
In the JHeadstart developers guide is stated that in a multi-developer-JHeadstart-project you should ensure that all the developers have the same Developer setup. In my case I turned out to be the only developer on this sub-project. But leaving the project others should be able to go further with it.
So I started my Windows Virtual Machine and took the time to setup a JDeveloper, Tortoise SVN client, download the Working copy of the workspace from SVN. That took me most of the time. Changing the workspace then was done in about a quarter.
JDeveloper Startup Path
JHeadstart and JDeveloper have absolute paths to libraries in the projects. It turns out to be quite handy to have all team members the same path to the libraries (as stated in the JHeartart Developers Guide). To enable that without the need to have each member physically install JDeveloper and the workingcopy of SVN in to the same directory, I crated a batch-file that creates two drives that map to the physical location.
I named the file drives.bat. It sets the s: drive to the folder that contains the trunk folder of your working copy and the w: drive to the home directory of jdeveloper (the root folder that contains the jdeveloper.exe):
subst s: e:\svn
subst w: e:\oracle\product\jdeveloper
Create a shortcut to the jdeveloper.exe on w:\ and start jDeveloper from that shortcut.
Install JHeadstart if not done allready:
In Jdeveloper goto Help=>Check for upates
Click next and choose install from local file.
Choose JHS10.1.3.3.85-INSTALL.ZIP and finisch the wizard.
Edit custom library
I used BPEL libraries because I needed to kickstart a BPEL process from a button in one of the screens. This library turned invalid since it could not find the jar-files following the original paths.
In Model Project properties goto libraries. Edit your custom OraBPEL Library. In my case I added the entries:
- W:\integration\lib\orabpel-boot.jar
- W:\integration\lib\orabpel-common.jar
- W:\integration\lib\orabpel-thirdparty.jar
- W:\integration\lib\orabpel.jar
- W:\j2ee\home\lib\ejb.jar
- W:\j2ee\home\oc4jclient.jar
Right click on the ViewController project and run Jheadstart Application Generator (JAG). The JAG will change the paths to the JHeadstart libraries according to the startup path of Jdeveloper.
Recompile the Model and the ViewController project.
This ensures you that the changes are applied correctly and the code compiles correctly. Now you can deploy it to your App-server and you should be able to run it using the Embedded OC4J server.
Run the ViewController project
If you add an appropriate ConnectionPool and DataSource in the Embedded OC4J Server (You can do that via Tools => Embedded OC4J Preferences) then you’ll be able to run the SchedulerUI in the Embedded OC4J. If you do so then you're sure the workspace is correct again.
Multiple Descriptor items in JHeadstart
In the past I used develop using Designer. Although it's already years ago I have warm memories to the tool. In Designer you could mark table-columns as descriptor-items, if I recollect correctly. I can't remember how it's done exactly and since I have noa running Designer install anymore I can't check. But I know that it was a check box on the item. So you can have multiple.
Descriptor Items are used to generate a reference on a details page to denote for which parent you are editing details.
In JHeadstart I found that you can give up only one item as a descriptor item on the group. In my latest project I had to create a maintenance application on a datamodel that had a table where the columns on their own were not descriptive enough. You could argue that I had to introduce such an attribute. For example a name or code attribute that is unique. But functionally the table did not need to have one. But the entity related to another entity for which I generated a detailgroup. And on that page a reference to the 'non-descriptive' table-row was generated. on one of it's columns. Most of the rows had the same value on the column though. So I wanted to connect all the attributes, together with a lookup attribute from another table and have that as a descriptor.
Luckily the solution I used was easy. And maybe as a JavaADF-JHeadstart expert you'd not be surprised. But for those who struggle, here's how I did it.
First I adapted the ViewObject of the parent-entity.
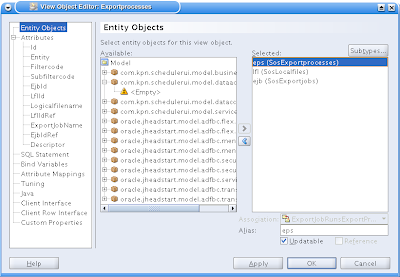
If needed add extra entity objects for attributes you want to relate to in your descriptor items. In an entity Object in ADF-Business Components by default the complete entity name is used for used as a table-alias. I normally I don't care, but if I want to adapt the ViewObject I find that inconvenient. So I replaced them with table three-letter-shortages.
Then under the Attribute nodes, click on the New Attribute button (bottom right):
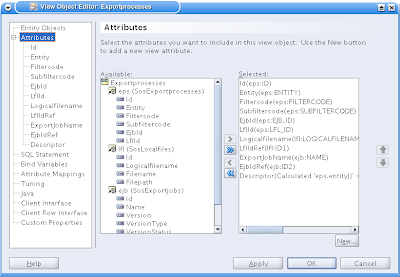
Then you get the following screen. Give the new attribute a name, check the box "Mapped to Column or SQL". Then you can give it an alias (the name the expression gets in the resulting SQL Statement". And give in an expression. I found it handy to first build up the sql statement with the particular expression in Pl/Sql developer and copy and paste it. Then I'm pretty shure it will work.
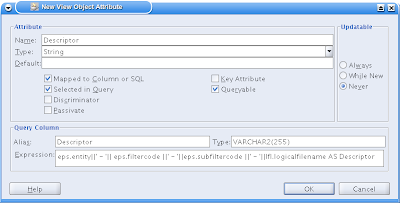 If you've done it correcly, following your needs, then the new attribute is found in the resulting SQL Statement:
If you've done it correcly, following your needs, then the new attribute is found in the resulting SQL Statement:
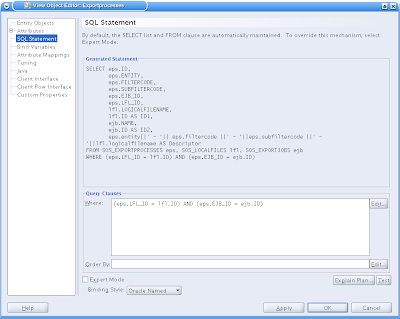
You can adapt it by giving an order by and an extra where-clause-condition. But I found it also handy to copy and paste the complete sql statement and try it in Pl/Sql Developer. That prevents me from surprises later on.
Having done that, things are straight forward. Go to the JHeadstart Application Definition Editor. And on the parent group add the descriptor-attribute as an item. Set the Java-Datatype etc. correctly but make it hidden (make sure all the 'show-on'-checkboxes are unchecked). Although it's hidden I gave it a prompt. Just to recognise it directly when I stumble on it.
Then on the group-page you can set the descriptor-item selector on the particular item.
The solution is simple. But it would be handy to have checkboxes on the items so that you could just check every item you want to have in the descriptor... (going the Designer way).
Descriptor Items are used to generate a reference on a details page to denote for which parent you are editing details.
In JHeadstart I found that you can give up only one item as a descriptor item on the group. In my latest project I had to create a maintenance application on a datamodel that had a table where the columns on their own were not descriptive enough. You could argue that I had to introduce such an attribute. For example a name or code attribute that is unique. But functionally the table did not need to have one. But the entity related to another entity for which I generated a detailgroup. And on that page a reference to the 'non-descriptive' table-row was generated. on one of it's columns. Most of the rows had the same value on the column though. So I wanted to connect all the attributes, together with a lookup attribute from another table and have that as a descriptor.
Luckily the solution I used was easy. And maybe as a JavaADF-JHeadstart expert you'd not be surprised. But for those who struggle, here's how I did it.
First I adapted the ViewObject of the parent-entity.

If needed add extra entity objects for attributes you want to relate to in your descriptor items. In an entity Object in ADF-Business Components by default the complete entity name is used for used as a table-alias. I normally I don't care, but if I want to adapt the ViewObject I find that inconvenient. So I replaced them with table three-letter-shortages.
Then under the Attribute nodes, click on the New Attribute button (bottom right):

Then you get the following screen. Give the new attribute a name, check the box "Mapped to Column or SQL". Then you can give it an alias (the name the expression gets in the resulting SQL Statement". And give in an expression. I found it handy to first build up the sql statement with the particular expression in Pl/Sql developer and copy and paste it. Then I'm pretty shure it will work.
 If you've done it correcly, following your needs, then the new attribute is found in the resulting SQL Statement:
If you've done it correcly, following your needs, then the new attribute is found in the resulting SQL Statement:
You can adapt it by giving an order by and an extra where-clause-condition. But I found it also handy to copy and paste the complete sql statement and try it in Pl/Sql Developer. That prevents me from surprises later on.
Having done that, things are straight forward. Go to the JHeadstart Application Definition Editor. And on the parent group add the descriptor-attribute as an item. Set the Java-Datatype etc. correctly but make it hidden (make sure all the 'show-on'-checkboxes are unchecked). Although it's hidden I gave it a prompt. Just to recognise it directly when I stumble on it.
Then on the group-page you can set the descriptor-item selector on the particular item.
The solution is simple. But it would be handy to have checkboxes on the items so that you could just check every item you want to have in the descriptor... (going the Designer way).
Tuesday, 13 January 2009
Better GMail and GCal
GMail and GCal on-line are great apps from Google. But the user experience can be even better with two smart add-ons: Better GMail 2 and Better GCal. You can download those for FireFox here:
They provide Greasmonkey java-scripts packaged into a separate Add-On.
The great thing on GCal is that you can create several calendars and share each one of them with a different set of peers. So I drum in a combo and I created a seperate calendar for that combo and invited the members to it. Each event in that calendar is available to all of them (provided that they create a Google-account).
But you can also add public calendars. I added for example:
They provide Greasmonkey java-scripts packaged into a separate Add-On.
The great thing on GCal is that you can create several calendars and share each one of them with a different set of peers. So I drum in a combo and I created a seperate calendar for that combo and invited the members to it. Each event in that calendar is available to all of them (provided that they create a Google-account).
But you can also add public calendars. I added for example:
- Basis school vakanties midden nederland (2006 - 2009)
- Joodse Feestdagen NL
- NL vakanties en feestdagen
- Week Numbers
Struck by Lightning
I know I'm a little stubborn. Actually I feel that it does not quite fit the Dutch word "eigenwijs", that means something like "know it better". And indeed on contrary to my colleagues I use OpenSuse Linux 64-bit, whereas they stick to 32-bit Windows. If they're happy with it, they should. But since my laptop has 4GB I want to use it all, so I wanted a 64-bit OS. And I want to drive myself in getting used to a unix-a-like OS, I use Linux. I learned all the windows versions from 3.1 to XP/Vista by doing. So the best way to learn an OS or an application for me is just by using it.
For reasons that lay in the line of the above, I use Thunderbird for years now (long before I stepped into Linux). And since recently I use Gmail.
Now I had a problem. I have a 64-bit Thunderbird, because of my 64-bit Linux. But the Lightning extension that you download at mozilla.com is a 32-bit and thus not fit for my Thunderbird. Therefor I used Sunbird with the Google Calendar Plugin.
Yesterday I stumbled upon the lightning plugin in Yast (the packagemanager of OpenSuse). So I installed it. And it worked. Apparently just recently they released a 64-bit Lightning. So I also installed the Google Calendar plug-in. But this reports that it misses modules. Also the Lightning plug-in reports that it is not updatable because of its source.
Googling I found the 64-bit Lighting plugin via this blog.
It states that you have to download the 0.9 release of the 64-bit Lighting at:
http://releases.mozilla.org/pub/mozilla.org/calendar/lightning/releases/0.9/contrib/linux-x86_64/
Download the file lightning-0.9-linux-x86_64.xpi and install it in Thunderbird.
You can find the Google plugin at: https://addons.mozilla.org/en-US/sunbird/addon/4631.
Download the add-ons and install them in Thunderbird. Then after restarting the plugins both work.
Adding a Google Calendar is really easy. In the calendar settings click on the XML button of the private addresses:

Then copy the link in the pop-up dialog.
In Lighting create a new calendar. Choose "on the network" in the first wizard page. Then choose "Google Calendar" on the second wizard page, and paste the link in the location. At the connect dialog provide the correct username/password to your gmail account. You can give in a color and a name in the last wizard page, before you click finish. When you right click on the calendar and choose properties, you can check the "cache" box. This requires a restart of Thunderbird but will cache the events. Mark that adding events to the calendar while not on-line will fail. For that you might want to have a local (on the computer) calendar. Being on-line you can toggle the events to the on-line calendar when updating them.
Adding calendars of work-mates or friends is just the same. By default the connect-dialog provides the username of your work-mate/friend. Provide your own credentials and you're done.
So thanks Sunbird, but now I have my Calendars right into Thunderbird you're done.
For reasons that lay in the line of the above, I use Thunderbird for years now (long before I stepped into Linux). And since recently I use Gmail.
Now I had a problem. I have a 64-bit Thunderbird, because of my 64-bit Linux. But the Lightning extension that you download at mozilla.com is a 32-bit and thus not fit for my Thunderbird. Therefor I used Sunbird with the Google Calendar Plugin.
Yesterday I stumbled upon the lightning plugin in Yast (the packagemanager of OpenSuse). So I installed it. And it worked. Apparently just recently they released a 64-bit Lightning. So I also installed the Google Calendar plug-in. But this reports that it misses modules. Also the Lightning plug-in reports that it is not updatable because of its source.
Googling I found the 64-bit Lighting plugin via this blog.
It states that you have to download the 0.9 release of the 64-bit Lighting at:
http://releases.mozilla.org/pub/mozilla.org/calendar/lightning/releases/0.9/contrib/linux-x86_64/
Download the file lightning-0.9-linux-x86_64.xpi and install it in Thunderbird.
You can find the Google plugin at: https://addons.mozilla.org/en-US/sunbird/addon/4631.
Download the add-ons and install them in Thunderbird. Then after restarting the plugins both work.
Adding a Google Calendar is really easy. In the calendar settings click on the XML button of the private addresses:

Then copy the link in the pop-up dialog.
In Lighting create a new calendar. Choose "on the network" in the first wizard page. Then choose "Google Calendar" on the second wizard page, and paste the link in the location. At the connect dialog provide the correct username/password to your gmail account. You can give in a color and a name in the last wizard page, before you click finish. When you right click on the calendar and choose properties, you can check the "cache" box. This requires a restart of Thunderbird but will cache the events. Mark that adding events to the calendar while not on-line will fail. For that you might want to have a local (on the computer) calendar. Being on-line you can toggle the events to the on-line calendar when updating them.
Adding calendars of work-mates or friends is just the same. By default the connect-dialog provides the username of your work-mate/friend. Provide your own credentials and you're done.
So thanks Sunbird, but now I have my Calendars right into Thunderbird you're done.
Thursday, 8 January 2009
Wireless network bridging with VMware Server 1.0.8
I recently wrote about how to enable your wireless network adapter for use as a bridge within VMWare Server 1.0.7. See here. It was not (much) more than a week after the article that VMWare came with VMware Server 1.0.8. Since I just had my wireless working I did not dare to switch. But today I just took the chance. And guess what? The VMWare people did not read my article! Now I have to repair it again. Since there is a solution I figured that they would repair it in 1.0.8.
But fortunately I had a copy of my repaired vmnet.tar. I also backupped the original vmnet.tar from the 1.0.7 installment. It turns out that the new vmnet.tar from 1.0.8 is exactly the same in size. I placed my repaired vmnet.tar here.
Just place it as root in: /usr/lib/vmware/modules/source and run vmware-config.pl again (as always it is wise to backup your original vmnet.tar). If you then bridge vmnet2 to your wireless lan adapter, and couple one of the ethernet-adapters of your VM to vmnet2 it will work again.
And now we hope that VMWare is willing to repair this their selves in the next release.
But fortunately I had a copy of my repaired vmnet.tar. I also backupped the original vmnet.tar from the 1.0.7 installment. It turns out that the new vmnet.tar from 1.0.8 is exactly the same in size. I placed my repaired vmnet.tar here.
Just place it as root in: /usr/lib/vmware/modules/source and run vmware-config.pl again (as always it is wise to backup your original vmnet.tar). If you then bridge vmnet2 to your wireless lan adapter, and couple one of the ethernet-adapters of your VM to vmnet2 it will work again.
And now we hope that VMWare is willing to repair this their selves in the next release.
Virtualize your (test) environment with VMWare
Many know that I'm an enthousiastic VMWare user. Even under Linux, I must say. Unfortunately I find that the support of Linux at VMWare is a little less then Windows. Where Windows user have a nice graphical interface to edit the vmnet settings, Linux users have to do it with a spartan shell script that recompiles the modules. Windows have automatic bridging, when I want to bridge my Wireless adapter I have to create a separate custom network adapter. But enough of the minuses: I'm very impressed with the software.
Oh yes, I know that there is Virtual Box. I haven't looked at that I must say. But honestly, VMWare does not give me any reasons for that.
Of course Oracle has also their virtualisation tool: Oracle VM. But that is not very usefull for consultants on the run. Unless you have a spare laptop that you can format, because Oracle VM runs directly on the hardware. Like VMWare ESX server. It's more a server product.
About a year ago (I think) I took the time to browse through VMWares product line and created an article that describes there product portfolio. It is in Dutch and maybe already somewhat out-dated, but you can download it here. I thought it might be usefull enough to share it though.
Browsing through their products rose my impression for them. What do you think, would it be possible for them to create a version of VMWare ESX Server, together with Live Motion technologies that span physical servers? Now they're able to transfer a live-running VM to another ESX server with nearly no outage. I learned that Oracle VM should be able to do that to. But then again the VM still runs on one physical server.
It would great if VMWare and/or Oracle would be able to run a single VM on several physical host. Then you have a grid-solution below the OS. If you look at the Oracle Database (9i Rac, 10g/11g Grid) than you talk about grid on the application level. Software providers as HP have Unix versions that have grid/failover capabilities on OS level. But I wait for VMWare Grid: grid between the hardware and the OS. What about Windows Server 2016 with 128 Processors because it runs on VMWare Grid? Or OpenSuse 13 with 256 processors?
For now, lets dream on...
Oh yes, I know that there is Virtual Box. I haven't looked at that I must say. But honestly, VMWare does not give me any reasons for that.
Of course Oracle has also their virtualisation tool: Oracle VM. But that is not very usefull for consultants on the run. Unless you have a spare laptop that you can format, because Oracle VM runs directly on the hardware. Like VMWare ESX server. It's more a server product.
About a year ago (I think) I took the time to browse through VMWares product line and created an article that describes there product portfolio. It is in Dutch and maybe already somewhat out-dated, but you can download it here. I thought it might be usefull enough to share it though.
Browsing through their products rose my impression for them. What do you think, would it be possible for them to create a version of VMWare ESX Server, together with Live Motion technologies that span physical servers? Now they're able to transfer a live-running VM to another ESX server with nearly no outage. I learned that Oracle VM should be able to do that to. But then again the VM still runs on one physical server.
It would great if VMWare and/or Oracle would be able to run a single VM on several physical host. Then you have a grid-solution below the OS. If you look at the Oracle Database (9i Rac, 10g/11g Grid) than you talk about grid on the application level. Software providers as HP have Unix versions that have grid/failover capabilities on OS level. But I wait for VMWare Grid: grid between the hardware and the OS. What about Windows Server 2016 with 128 Processors because it runs on VMWare Grid? Or OpenSuse 13 with 256 processors?
For now, lets dream on...
As (probably) every other consultant I don't like the task of documenting my source. It's necessary, but boring. And what do you document and what not? And what if you add a parameter? It would be handy if you can generate your documentation, wouldn't it?
And it can: using the pl/sql doc plug-in of Pl/Sql Developer.
See http://www.allroundautomations.nl/plsplsqldoc.html.
Already a few years a I wrote an article on it. For our Dutch readers and our non-dutch readers who are that linguistic that they haven't any problems with our beautiful language, you can download it here.
And it can: using the pl/sql doc plug-in of Pl/Sql Developer.
See http://www.allroundautomations.nl/plsplsqldoc.html.
Already a few years a I wrote an article on it. For our Dutch readers and our non-dutch readers who are that linguistic that they haven't any problems with our beautiful language, you can download it here.
Explore your Windows Processes
Many consultants that use Windows find that the Taskmanager of windows is pretty rudimentary. Also you might have encountered that files are locked by processes that you're not aware of. Or process that you can't manage to kill using Taskmanager. Then the Process explorer tool of Sysinternals is very usefull. Sysinternals is now part of Microsoft (already since a few years) but the tool is still available for free. It is such a great tool that I recommend to replace the taskmanager by it.
You can download the tool at http://download.sysinternals.com/Files/ProcessExplorer.zip
For our dutch readers I have an article on Process Explorer that I wrote a few years ago. You can download it here.
You can download the tool at http://download.sysinternals.com/Files/ProcessExplorer.zip
For our dutch readers I have an article on Process Explorer that I wrote a few years ago. You can download it here.
Wednesday, 7 January 2009
Xpath error in BPEL assign after transform step
Recently I ran into an xpath error in an assign step in BPEL. The error denoted that the xpath expression is in error because of a node not found. Unfortunately it does not quite clearly state if it is about the "from"-xpath expresssion or the "to"-expression. And strangely enough the copy-rule-wizard lets you select the proper element, so the xpath-expression is clearly correct!
I found out that in this case I had a xslt-transform-step somewhere before the assign step. In this step I initialized the variable, but in the later assign step I assigned some other elements that I could not determine during the transform, because these values came from other variables.
In the XSLT I did not explicitly fill the elements that I assigned later. Apparently the transform step creates only those elements that are explicitly named in the XSLT. Those that are not defaulted or filled, are thus not created.
I solved it by adding the node element to the xslt, filling it with a simple xsl:text element with a space or something.
So I conclude that an non-existing node is apparently not the same as an empty element!
I found out that in this case I had a xslt-transform-step somewhere before the assign step. In this step I initialized the variable, but in the later assign step I assigned some other elements that I could not determine during the transform, because these values came from other variables.
In the XSLT I did not explicitly fill the elements that I assigned later. Apparently the transform step creates only those elements that are explicitly named in the XSLT. Those that are not defaulted or filled, are thus not created.
I solved it by adding the node element to the xslt, filling it with a simple xsl:text element with a space or something.
So I conclude that an non-existing node is apparently not the same as an empty element!
Monday, 5 January 2009
Xpath expressions with namespaces on XMLType
I used to use XMLTypes with xml where I tend to prevent the usage of namespaces. Namespaces make things difficult where they are often unneeded. That is I experienced that it is hard. An expression like '/level1/level2/level3' is much simpeler then '/ns1:level1/ns2:level2/ns3:level3'. Especially if you don't know how to give in the particular namespaces.
Lately I wanted to store the results of a BPEL Process in the database to be able to query parts from that in a later process. Actually I processed several files in the one process and wanted to query the statuses in the later process again. If you work with BPEL you cannot avoid using namespaces. I also wanted to put the results in an XMLtype as is, since it prevented me to create a complete datamodel. A simple xmltype-table suffices.
I then created a pl/sql function with the filename as a parameter that fetched the right row in the results table and gave back the xmltype column in which the status of that file was stored. But then, how to query it with XPath?
I knew the xmltype.extract() function. But what next? You can avoid namespaces by using the local-name() xpath function, but then it is a little hard to get the value of the particular file.
Luckily the extract() function has another parameter, the namespace string:
extract(XMLType_instance IN XMLType,
XPath_string IN VARCHAR2,
namespace_string In VARCHAR2 := NULL) RETURN XMLType;
This namespace string can contain the namespace declarations to be used in an xpath expression. The namespace declarations look like:
namespace-shortage=uri
for example
ns1="http://www.example.org/namespace1"
You can have multiple declarations separated by white space.
An example is as follows:
Read more about it on page 4.6 of: http://download-uk.oracle.com/docs/cd/B19306_01/appdev.102/b14259.pdf.
Mark also that there are actually two functions: extract() and extractvalue(). Extract() returns an xmltype, that can be 'sub-queried'. The extractvalue() function returns the datatype of the variable that the value is assigned to. With the xmltype functions getstringval(), getclobval(), etc. you can also get the particular value of a node of the xmltype. However, there is a slight difference between the result of the getstringval() and correspondingfunctions and Extractvalue. And that is that the Extractvalue returns the unescaped value of the node (the encoding entities are unescaped), while getstringval() returns the value with the entity encodings intact .
Lately I wanted to store the results of a BPEL Process in the database to be able to query parts from that in a later process. Actually I processed several files in the one process and wanted to query the statuses in the later process again. If you work with BPEL you cannot avoid using namespaces. I also wanted to put the results in an XMLtype as is, since it prevented me to create a complete datamodel. A simple xmltype-table suffices.
I then created a pl/sql function with the filename as a parameter that fetched the right row in the results table and gave back the xmltype column in which the status of that file was stored. But then, how to query it with XPath?
I knew the xmltype.extract() function. But what next? You can avoid namespaces by using the local-name() xpath function, but then it is a little hard to get the value of the particular file.
Luckily the extract() function has another parameter, the namespace string:
extract(XMLType_instance IN XMLType,
XPath_string IN VARCHAR2,
namespace_string In VARCHAR2 := NULL) RETURN XMLType;
This namespace string can contain the namespace declarations to be used in an xpath expression. The namespace declarations look like:
namespace-shortage=uri
for example
ns1="http://www.example.org/namespace1"
You can have multiple declarations separated by white space.
An example is as follows:
declare xp_no_data_found exception; pragma exception_init(xp_no_data_found, -30625); l_xpath varchar2(32767) := '/ns1:level1/ns2:level2/ns3:level3'; l_nsmap varchar2(32767) := 'ns1="http://www.example.org/namespace1" ns2="http://www.example.org/namespace2" ns3="http://www.example.org/namespace3"'; l_xml xmltype; l_clob clob; begin l_xml := function_that_gets_an_xmltype_value(); l_clob := l_xml.extract(l_xpath, l_nsmap).getclobval(); end;
Read more about it on page 4.6 of: http://download-uk.oracle.com/docs/cd/B19306_01/appdev.102/b14259.pdf.
Mark also that there are actually two functions: extract() and extractvalue(). Extract() returns an xmltype, that can be 'sub-queried'. The extractvalue() function returns the datatype of the variable that the value is assigned to. With the xmltype functions getstringval(), getclobval(), etc. you can also get the particular value of a node of the xmltype. However, there is a slight difference between the result of the getstringval() and correspondingfunctions and Extractvalue. And that is that the Extractvalue returns the unescaped value of the node (the encoding entities are unescaped), while getstringval() returns the value with the entity encodings intact .
Friday, 2 January 2009
Free your debug Session
Recently I had to build, test and debug some Pl/Sql. I use my all time favourite tool Pl/Sql Developer. But it happens when debugging Pl/Sql that for no apparent reason the debug-session hangs. Especially when hitting the Break button in Pl/Sql Developer, it may happen.
When it happens you'll have to kill Pl/Sql Developer the hard way, using Taskmanager. Because it refuses to quit while there is a session running.
Fortunately, there is a pretty simple solution.
When your test script looks like:
Then just declare an extra variable l_time_out of data type number. Then set a time of for example 5 seconds. using the dbms_debug.set_timeout:
When Pl/Sql Developer looses the connection to the debug session the debug session will be freed after the timeout. Pl/Sql Developer gets the control back and you can go on with compiling and debugging.
You can add it easily to the default test template. Unfortunately Pl/Sql Developer does not use the template when you do right-click->test on a program-unit.
For that you could create a macro that adds the code to your test script, and connect it to a key-stroke.
When it happens you'll have to kill Pl/Sql Developer the hard way, using Taskmanager. Because it refuses to quit while there is a session running.
Fortunately, there is a pretty simple solution.
When your test script looks like:
-- Created on 1/2/2009 by MAKKER declare -- Local variables here i integer; begin -- Test statements here :result := sos_log.log_run(p_schedule_id => :p_schedule_id, p_status => :p_status); end;
Then just declare an extra variable l_time_out of data type number. Then set a time of for example 5 seconds. using the dbms_debug.set_timeout:
declare l_time_out number; -- Local variables here i integer; begin l_time_out := dbms_debug.set_timeout(5); -- Call the function :result := sos_log.log_run(p_schedule_id => :p_schedule_id, p_status => :p_status); end;
When Pl/Sql Developer looses the connection to the debug session the debug session will be freed after the timeout. Pl/Sql Developer gets the control back and you can go on with compiling and debugging.
You can add it easily to the default test template. Unfortunately Pl/Sql Developer does not use the template when you do right-click->test on a program-unit.
For that you could create a macro that adds the code to your test script, and connect it to a key-stroke.
Subscribe to:
Posts
(
Atom
)




